

Замещение данных
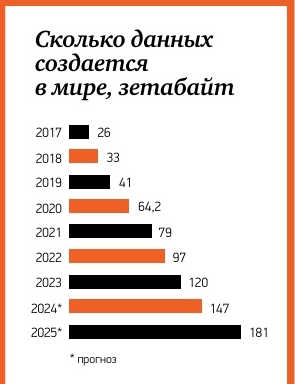
Объем данных с каждым днем в мире только увеличивается. Ежедневно в мире создается 328,77 млн терабайт данных, причем 90% их мирового объема было произведено за последние три года – по одному этому факту легко понять, как стремительно растет количество данных в IT-системах.
Мировой рынок big data увеличился в прошлом году до 220 млрд долларов, следует из исследования консалтинговой компании Marketsand Markets. По прогнозам, к 2028 году он может почти удвоиться и достигнуть 401 млрд долларов. Российский рынок составляет лишь 1,5% мирового. По базовому сценарию российский рынок до конца 2024 года вырастет до 319 млрд рублей, говорят в Ассоциации участников рынка больших данных (АБД). При наихудшем сценарии – всего до 189 млрд рублей.

За последние два года российский рынок решений для big data претерпел серьезные изменения: с него ушли многие иностранные вендоры со своими системами хранения данных (СХД), такие как Dell, Hitachi, Huawei, NetApp. Западные облачные сервисы также оказались недоступны в России. Весной текущего года AWS, Microsoft и SAP закрыли доступ российским компаниям к своему облачному ПО. А спустя месяц Роскомнадзор в ответ сам заблокировал для россиян облачные сервера от Amazon. Зарубежные системы управления базами данных (СУБД) тоже теперь не достать в России. Создатели популярных решений Oracle и Microsoft свернули бизнес еще в 2022 году.
Их тут же взялись замещать российскими решениями. Раньше для хранения данных обычно используются созданные международными компаниями опенсорсные системы (на основе открытого кода, то есть их можно дорабатывать под нужды конкретных компаний. – Прим. ред.) s3 или hdfs. Для стриминга (обеспечения постоянного потока передачи данных. – Прим. ред.) – Kafka, для обработки – Hadoop и Spark. Для DHW (хранилище структурированных данных, помогающим руководителям бизнеса увидеть цельную картину, что происходит с компанией. – Прим. ред.) нужны системы Hive, Impala, Greenplum, Clickhouse, рассказывает архитектор Big Data компании Softline Digital Дмитрий Пухов.
«Российские компании сегодня собирают похожие системы в свои вендорские сборки и продают готовые решения с сопровождением», – отмечает он.
Среди локальных решений по хранению данных можно выделить российские RuBackup, Basis Virtual Protect, Altaro VM Backup, YADRO, AeroDisk, Гравитон, «Береста», продолжает технический директор компании САТЕЛ, занимающейся разработкой ПО и развертыванием IT-инфраструктуры, Евгений Мосин. По его мнению, эти продукты показывают, что российский рынок в этом сегменте уже достаточно развит.
Западные облачные сервисы также удалось импортозаместить. По словам Пухова на замену западным облакам Amazon, Azure, Google Cloud пришли российские Yandex Cloud, SberCloud, VC. Также на рынке сегодня пользуется спросом Национальная облачная платформа «Ростелекома», «Облако» Mail.ru и CloudMTS, продолжает Евгений Мосин.
Попутно содержать массивы информации стало намного дороже. В 2022 году цены на отечественные серверы СХД поднялись в полтора раза. Российские облачные провайдеры также повысили стоимость аренды. Например, Yandex Cloud весной 2022 года поднял цену на свои услуги на 30–60%. По оценкам Евгения Мосина, стоимость облачных серверов только в 2023 году в России выросла в среднем на 15%. Это связано со скачком цен на оборудование, дефицитом компонентов и увеличением логистических затрат.
Раньше крупные игроки могли покупать большое число серверов, теперь же им приходится наращивать их осторожнее. К примеру, у страховых компаний стоимость серверов для обработки клиентских данных может легко доходить до 100 млн рублей. У крупных же банков или телеком-операторов бюджеты на управление данными могут быть нескольких миллиардов рублей в год.
При этом эффект от использования больших данных не всегда покрывает затраты на их сбор, хранение и анализ. «Один из крупнейших российских ретейлеров накопил более 5 петабайт данных, но использовал лишь около 25% из них. Высокие затраты на хранение информации и неэффективное использование данных привели к тому, что инвестиции в инфраструктуру оказались значительно выше ожидаемой выгоды от анализа», – рассказывает Евгений Мосин, добавляя, что компании с устаревшей инфраструктурой могут столкнуться с высокими затратами без ощутимых выгод.
Многие компании пытаются найти выход, снижая расходы на обработку и анализ больших данных. Для этого они, по словам Мосина, оптимизируют хранение информации, переходят на облачные решения с оплатой за фактическое использование (pay-as-you-go). Также стараются комбинировать разные схемы хранения данных: например, используют «горячее» хранение (данные из таких хранилищ можно моментально извлечь), для которого нужны более мощные серверы и сетевые каналы, и более дешевое, «холодное» хранение (данные извлекаются редко).

Ожидание данных
Компании и IT-специалисты сходятся в том, что основная ценность big data в возможности их анализа. С их помощью можно лучше понять поведение клиентов, найти ошибки в бизнес-процессах и работе на производстве.
Чаще всего большие данные используют сервисные компании в финансовом секторе, в телекоме и IT, говорится в исследовании Института статистических исследований и экономики знаний (ИСИЭЗ) НИУ ВШЭ «Мониторинг цифровой трансформации бизнеса». И это неслучайно. По оценкам аналитиков, выгоднее всего применять big data в сферах, где происходит большое число контактов с клиентами. Это позволяет лучше прогнозировать их поведение. Поэтому большие данные так любят собирать рекламные агентства и компании в сфере ретейла. Последние, к примеру, могут с их помощью повысить эффективность маркетинга, оптимизировать ассортимент товаров и подобрать для них более взвешенную цену.
В производстве big data позволяет выработать новые подходы. И дает возможность более эффективно проводить ремонт оборудования – не по регламенту, а на основе прогнозов, когда оно выйдет из строя.
По мнению аналитика сервиса для ведения товарного учета в розничной торговле «Контур.Маркета» Дарьи Жигалиной, зарабатывать на больших данных – это, скорее, прерогатива крупных компаний. Неслучайно именно крупный бизнес сегодня активнее вкладывается в работу с данными.
Как примеры монетизации данных Жигалина приводит кейс телеком-операторов, у которых есть аудиторные данные (совокупность характеристик аудитории. – Прим. ред.) по разным сегментам клиентов. Они позволяют операторам эффективнее проводить рекламные кампании. «Ценность данных состоит в их объемах и интересных пересечениях, на которых можно построить выводы», – отмечает эксперт.
По словам генерального директора компании «Логвинов Консалтинг Сервис» Олега Логвинова, на больших данных сегодня зарабатывают совсем немногие. «Лишь малая часть компаний использует действительно «большие данные». Пока это делает только бизнес из сферы услуг – все те же банки, телеком, ретейлеры. Другие к этому еще только идут и пока не видят никакой в этом потребности», – говорит эксперт.
В то же время целые отрасли экономики даже не приступали к использованию больших данных – соответственно, пока не знают, какие именно эффекты могли бы от этого получить. По словам Олега Логинова, в аутсайдерах сегодня в области big data оказываются многие компании нефтегазового сектора, энергетики, горнодобывающей, сельскохозяйственной отрасли. «Увы, но большинство структур данного сегмента все еще не уделяет внимания тому, как извлекать выгоду «из данных», поскольку мало кто из них располагает стратегией развития данных как реального актива. И это при том, что буквально все уже имеют компьютеры и должны работать с массой генерируемых данных», – отмечает эксперт.
Многие компании просто не знают, как данные правильно связывать, анализировать, безопасно хранить. «Да, появляются локальные датасеты (структурированные массивы данных. – Прим. ред.), но дезинтегрированные между собой и не поддающиеся инструментам глубокой аналитики, машинного обучения», – заключает Логвинов.
Отрезвление данных
Сейчас мы находимся на этапе, когда первоначальная эйфория от перспектив big data сменилась если не разочарованием, то неким отрезвлением. Многие компании столкнулись с тем, что обработать скопившиеся данные и извлечь из них пользу возможно далеко не всегда. По словам разработчика Workerly Емельяна Мараховского, клиентских данных у компаний сегодня скопилось много, но часто эти данные невозможно проанализировать.
«Далеко не все можно с помощью этих данных предсказать, не везде можно построить корректную модель, которая даст тот результат, который ждет заказчик. Кроме того, такая модель может быть в одно время точна, а через какое-то время уже не давать результат. На первый взгляд кажется, что данных собрали много, но только по части предикторов (то есть по нескольким параметрам. – Прим. ред.), а нужны и другие предикторы, которые не были учтены. В результате будет недостаточно данных для работы модели», – рассказывает он.
Правда, в будущем, по его мнению, данных собирать меньше не станут, так как средств хранения становится только больше, возможности здесь у компаний расширяются. Но, очевидно, относиться к этим массивам информации будут более критично.
Есть уже и неоправдавшиеся ожидания. Например, персонализированная реклама, сделанная на основе big data, становится неэффективной. Так, по данным исследования «Яндекса» и аналитического агентства A2.Research, треть жителей страны предпочитают не брать трубку, когда звонят с незнакомых номеров. То есть рекламные сообщения до них просто не доходят. По словам же Евгения Мосина, 25% видеорекламы обычно просматривают боты.
Банкам большие данные помогают в числе прочего проводить клиентский скоринг. Но в последнее время аналитики пришли к выводу, что большое количество параметров для анализа не всегда гарантирует правильную оценку платежеспособности клиента. Для нее достаточно знать зарплату, место работы и кредитную историю, остальные параметры могут только запутать систему.
Поэтому и бизнесу, и разработчикам решений для больших данных сейчас придется еще раз поставить для себя вопрос: надо ли собирать данные, какие и для чего? И найти на него честный ответ в новой экономической и информационной реальности.
Утекающие в сеть
Хранение больших объемов данных ставит перед компаниями еще один серьезный вызов. Базы надо защищать от наносящих серьезные имиджевые издержки утечек. Здесь стоит вспомнить грандиозный скандал, в который в прошлом году угодил американский сайт генетических тестов 23andMe, допустивший утечку персональных данных 6,9 млн клиентов. Хакеры просто взломали учетную запись одного из админов, скачали все данные и выложили их в даркнет.
Россия же, по информации Positive Technologies, и вовсе возглавляет рейтинг стран по числу объявлений о продаже баз данных компаний в даркнете. На российские объявления приходится около 10% от общего числа объявлений за первое полугодие 2024 года. То есть наши данные в повышенной зоне риска.
По словам руководителя российского исследовательского центра «Лаборатории Касперского» Дмитрия Галова, за первые 8 месяцев 2024 года в России выросло на 60% число веб-угроз по сравнению с аналогичным периодом 2023 года. Веб-угрозы, или онлайн-угрозы, – это категория рисков кибербезопасности, связанных с использованием интернета, которые могут вызывать нежелательные события или действия. Веб-угрозы могут возникать вследствие уязвимостей систем конечных пользователей, ошибок разработчиков или операторов веб-сервисов, а также уязвимостей в самих сервисах.
Самая большая угроза для данных – вирусы-шифровальщики. «В России за первые 8 месяцев 2024 года на 8% выросло число атак с использованием шифровальщиков по сравнению с аналогичным периодом 2023 года», – рассказывает руководитель российского исследовательского центра «Лаборатории Касперского» Дмитрий Галов.
Руководитель направления F.A.C.C.T. Attack Surface Management Николай Степанов отмечает, что сейчас в России действует множество группировок, которые атакуют с помощью шифровальщиков как крупный, так и малый бизнес. «Характер атак в последнее время изменился. Если для зарубежных атак выбираются крупные цели, чтобы получить максимально возможный выкуп, то в России чаще под прицел попадают ВПК, ТЭК, IT, телеком. Это связано с тем, что злоумышленники не только хотят получить выкуп, но и украсть данные, параллельно нарушив цепочку производства», – объясняет эксперт.
Часто преступники совершаются и простые кражи данных (без шифрования), а также запускают «вайперы» (от англ. viper – «гадюка) – программы, которые уничтожают данные на зараженных компьютерах.
Защититься от утечек персональных данных в случае кибератак на компании обычные клиенты не могут никак. Все дело в том, что данные пользователей часто собираются без их ведома. Теоретически россияне могут попросить компании удалить их персональные данные – личные фото, имя, телефон и т. п. – из клиентских баз. Соответствующий закон был принят еще в 2020 году. Но у компаний остается возможность этого не делать, проследить за ее действиями никто не сможет.
Давая согласие на обработку данных, пользователи не могут оценить, насколько надежна система защиты данных у провайдера. «Проверить это можно лишь в том случае, если они используют open-source (с открытым кодом – Прим. ред.) сервисы, – рассказывает основатель проекта BioData Станислав Скакун. – Таких компаний мало: например, недавно западный VPN-сервис Proton (запрещенный в России) специально открыл свой код и провел независимый аудит, чтобы показать, как в нем обрабатываются данные пользователей. Но такие практики сегодня не распространены, так как большинство компаний по понятным причинам предпочитают использовать продукты с закрытым кодом».
Продавцы датасетов
В будущем обычные люди, а не только крупные компании, смогут получить свой кусок пирога – выгоду от распространения данных. Крупные компании будут им за их распространение платить, считает ряд опрошенных «ПСБ Деньги» разработчиков.
«Данные через некоторое время данные будут расти в цене. Все больше компаний будет платить за датасеты для обучения нейросетей. Это будет связано с развитием машинного обучения, которое базируется именно на массивах данных», – говорит Олег Логвинов.
Правда, по словам Станислава Скакуна, в России никаких обсуждений возможности прямой продажи данных сегодня не ведется. У компаний также пока нет желания платить за данные. Тем не менее стартап BioData является инструментом для сбора данных с возможностью использования в научных целях. «Мы уже разработали инструмент для анонимизированного сбора данных о здоровье и активности пользователей. Через наше приложение пользователи загружают информацию о питании, свои медицинские анализы, а в скором времени мы добавим и ответы на опросники, данные с устройств, отслеживающих сон и спортивную активность. Да, конечно, мы пока не в состоянии им за эти данные платить, но уже сейчас предоставляем им какие-то бонусы – например, бесплатно определяем их биологический возраст», – рассказывает Скакун.
Разработчик говорит, что в будущем хочет создать инструменты монетизации этих данных для пользователей, давая пользователю возможность соглашаться на их использование для научных исследований. И делиться доходом от продажи такой лицензии с обычными людьми, загрузившими их в приложение. Научные команды могли бы с их помощью проверять свои гипотезы. Также их можно использовать для обучения нейросетей.
Евгений Мосин считает, что подобные концепции «цифрового суверенитета», когда пользователи сами распоряжаются своими данными, в будущем станут реальными. Уже сегодня на рынке есть похожие решения. Например, проект Brave Browser с функцией блокировки рекламы, который предлагает пользователям получать вознаграждение в виде криптовалюты за просмотр рекламных объявлений, когда они дают согласие на их показ. Или блокчейн-проекты Datum и Ocean Protocol – платформы для управления и продажи данных пользователями.
Однако не все эксперты уверены в реалистичности таких проектов. Заместитель директора подразделения консалтинга DIS Group Сергей Евтушенко отметил, что рынок к таким предложениям относится с настороженностью, так как данная концепция требует проработки, в том числе сложных технических процессов. Генеральный директор АНО «Национальный центр компетенций по информационным системам управления холдингом» (НЦК ИСУ) Кирилл Семион добавляет, что тоже не верит в реализацию этой концепции, так как она потребует кардинального изменения всей нормативной базы.
Изображение на обложке сгенерировано с помощью нейросети Midjourney